PS2ΒΡœ‘Ω®ΡΎ«ΕΈΜΩμ2560bitΘ®ΡψΟΜΩ¥¥μΘ§ «ΝΫ«ßΈεΑΌΝυ °Θ©ΒΡeDRAMΘ§Υδ»Μ÷Μ”–4MBΘ§ΒΪ «ΫαΚœ«ΑΟφΒΡΗτ––δ÷»ΨΡΘ ΫΘ§Ω…“‘ ¬ Β…œΉωΒΫ”Ο“Μ’≈ΆΦΒΡΡΎ¥φ”ΟΝΩ Βœ÷Double BufferΓΘΕχ«“ΡΎ≤Ω¥Ϊ δΥΌ¬ ΦΪΗΏΘ§÷ΓΜΚ≥εΖ÷±π”–1024bit–¥ΚΆΕΝΉήœΏΘ®ΒΞœρ19.2GB/s*2»ΪΥΪΙΛΘ©Θ§Υυ“‘Ω…“‘ΉωΒΫGPU‘Ύδ÷»ΨΒΡΆΨ÷–Ά§ ±Ω…“‘Ε‘δ÷»ΨΚΟΒΡΆΦœώΫχ––Ης÷÷Φ”ΙΛΘ§“≤≤ΜΒΔΈσœ‘ ΨΓΘΕχΈΤάμΒΞ‘Σ”–ΒΞΕάΒΡ512bitΕΝ–¥ΉήœΏΘ®9.6GB/sΑκΥΪΙΛΘ©Θ§δ÷»ΨΆΨ÷–Ε‘ΈΤάμΒΡ–¥–η«σ≤Δ≤ΜΗΏΘ®Φ«ΉΓΘ§δ÷»Ψ δ≥ωΉΏΒΡ «ΒΞΕάΒΡ÷ΓΜΚ≥εΉήœΏΘ§Υυ“‘ Βœ÷Render to texture≤Δ≤Μ–η“ΣΦΖ’Φ512bitΒΡΈΤάμΉήœΏΘ©Θ§’βΗωΕΝ»ΓΥΌΕ»Ω…“‘¬ζΉψΥυ”–δ÷»ΨΒΡΈΤάμ¥φ»Γ–η«σΓΘHsvΩλ≥δΆχ¬γ
 HsvΩλ≥δΆχ¬γ HsvΩλ≥δΆχ¬γ
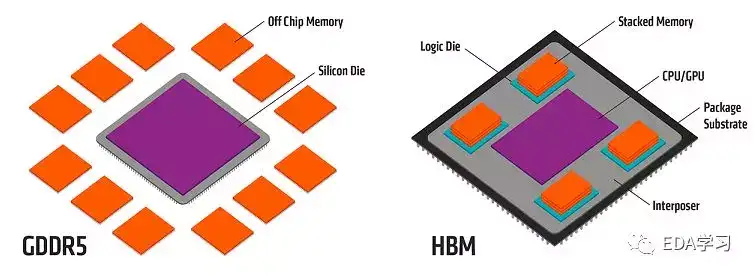
1ΘΚ ≤Ο¥ «HBMΘΚHsvΩλ≥δΆχ¬γ
HBM==High Bandwidth Memory «“ΜΩν–¬–ΆΒΡCPU/GPU ΡΎ¥φ–ΨΤ§Θ®Φ¥ “RAM”Θ©Θ§Τδ ΒΨΆ «ΫΪΚήΕύΗωDDR–ΨΤ§Ε―Βΰ‘Ύ“ΜΤπΚσΚΆGPUΖβΉΑ‘Ύ“ΜΤπΘ§ Βœ÷¥σ»ίΝΩΘ§ΗΏΈΜΩμΒΡDDRΉιΚœ’σΝ–ΓΘœ»Ω¥ΗωΤΫΟφΆΦΘΚHsvΩλ≥δΆχ¬γ
HsvΩλ≥δΆχ¬γ
 HsvΩλ≥δΆχ¬γ HsvΩλ≥δΆχ¬γ
HsvΩλ≥δΆχ¬γ
÷–ΦδΒΡdie «GPU/CPUΘ§Ήσ”“2±Ώ4Ηω–ΓdieΨΆ «DDRΩ≈ΝΘΒΡΕ―ΒΰΓΘ‘ΎΕ―Βΰ…œΘ§œ÷‘Ύ“ΜΑψ÷Μ”–2/4/8»ΐ÷÷ ΐΝΩΒΡΕ―ΒΰΘ§ΝΔΧε…œΉνΕύΕ―Βΰ4≤ψ.HsvΩλ≥δΆχ¬γ
- ‘ΌΩ¥“ΜΗωHBM DRAM 3DΆΦ–ΈΘΚ
HsvΩλ≥δΆχ¬γ
 HsvΩλ≥δΆχ¬γ HsvΩλ≥δΆχ¬γ
HsvΩλ≥δΆχ¬γ
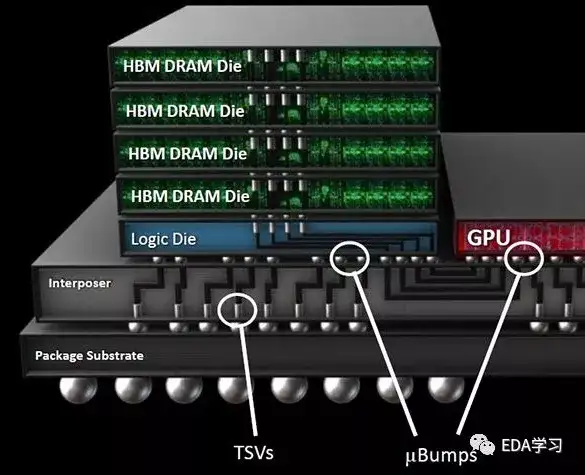
- DRAMΆ®ΙΐΕ―ΒΰΒΡΖΫ ΫΘ§Βΰ‘Ύ“ΜΤπΘ§Die÷°Φδ”ΟTVSΖΫ ΫΝ§Ϋ”
- DRAMœ¬Οφ «DRAM¬ΏΦ≠ΩΊ÷ΤΒΞ‘Σ, Ε‘DRAMΫχ––ΩΊ÷Τ
- GPUΚΆDRAMΆ®ΙΐuBumpΚΆInterposerΘ®ΤπΜΞΝΣΙΠΡήΒΡΙηΤ§Θ©Ν§Ά®
- Interposer‘ΌΆ®ΙΐBumpΚΆ Substrate(ΖβΉΑΜυΑεΘ©Ν§Ά®ΒΫBALL
- ΉνΚσBGA BALL Ν§Ϋ”ΒΫPCB…œΓΘ
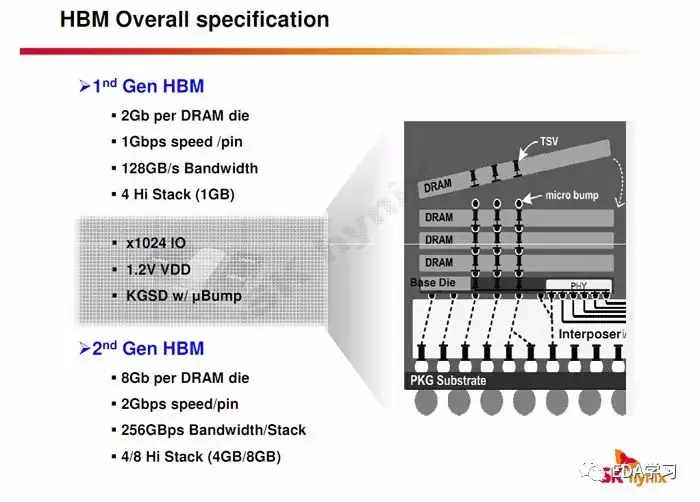
2ΘΚHBMΦΦ θΧΊ…ΪΘΚΒΫœ÷‘ΎΈΣ÷Ι…ζ≤ζΒΡ÷Μ”–1-2¥ζΘ§ΒΎ3¥ζΒΡSPECΗ’Η’±ΜΕ®“εΓΘHsvΩλ≥δΆχ¬γ
HsvΩλ≥δΆχ¬γ
 HsvΩλ≥δΆχ¬γ HsvΩλ≥δΆχ¬γ
HsvΩλ≥δΆχ¬γ
άœΧζΟ«Θ§1024ΈΜΩμΘ§ 256Gbps¥χΩμΘ§ΩΩΘΓ”–ΟΜ”–Ηψ¥μΘ§ΟΜ”–Θ§’βΗω’φΟΜ”–ΓΘHsvΩλ≥δΆχ¬γ
ΝμΨίœΛΘ§AMDΦΑNVIDIAœ¬¥ζœ‘Ω®ΕΦΜα¥ν≈δ4ΉιHBMœ‘¥φΘ§Β»–ßΈΜΩμ4096bitΘ§Ήή¥χΩμΩ…¥ο1024GB/sΘ§“≤ΨΆ «NVIDIA÷°«Α–ϊ¥ΪΒΡTB/sΦΕ±π¥χΩμΓΘHsvΩλ≥δΆχ¬γ
’β «“ΣΡφΧλ―ΫΘΓHsvΩλ≥δΆχ¬γ
3:ΈΣ ≤Ο¥“ΣHBM:HsvΩλ≥δΆχ¬γ
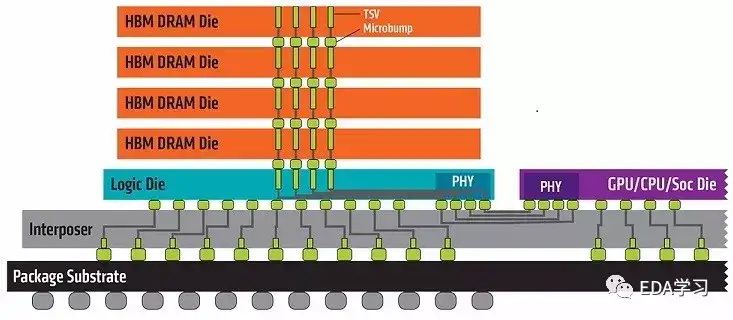
HBM Ε―’ΜΟΜ”–“‘ΈοάμΖΫ Ϋ”κ CPU Μρ GPU Φ·≥…Θ§Εχ «Ά®Ιΐ÷–Ϋι≤ψΫτ¥’ΕχΩλΥΌΒΊΝ§Ϋ”Θ§HBM ΨΏ±ΗΒΡΧΊ–‘ΦΗΚθΚΆ–ΨΤ§Φ·≥…ΒΡ RAM“Μ―υΓΘHsvΩλ≥δΆχ¬γ
HBM Ε―’ΜΖΫ ΫΩ…“‘ Βœ÷ΗϋΕύΒΡIO ΐΝΩΘ§1024ΈΜΓΘHsvΩλ≥δΆχ¬γ
HsvΩλ≥δΆχ¬γ
 HsvΩλ≥δΆχ¬γ HsvΩλ≥δΆχ¬γ
HsvΩλ≥δΆχ¬γ
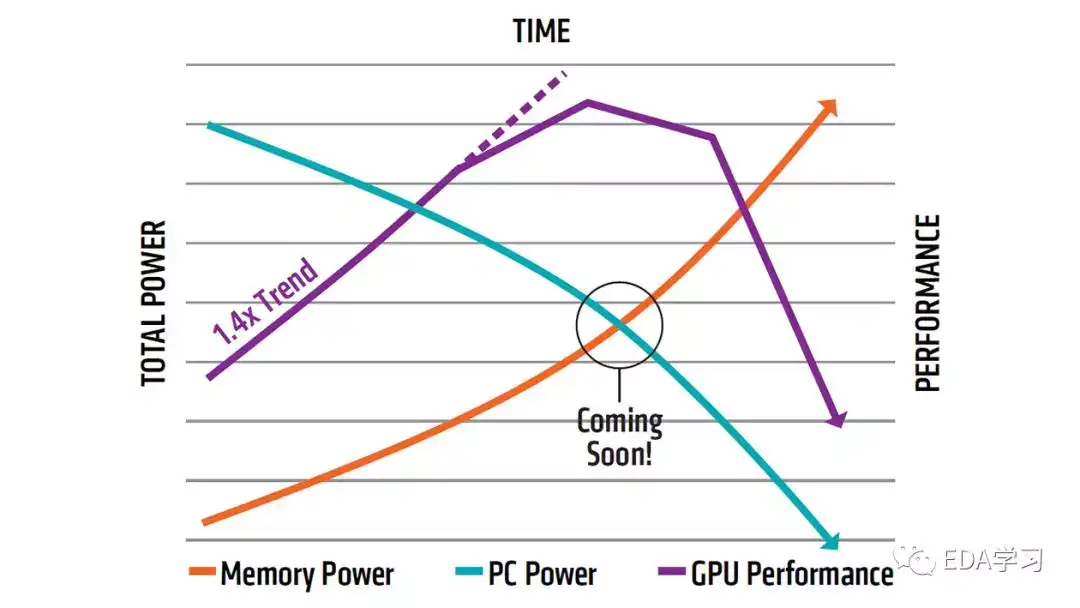
ΥφΉ≈œ‘Ω®–ΨΤ§ΒΡΩλΥΌΖΔ’ΙΘ§»ΥΟ«Ε‘ΩλΥΌ¥Ϊ δ–≈œΔΘ®“¥χΩμ”Θ©ΒΡ“Σ«σ“≤‘Ύ≤ΜΕœΧαΗΏΓΘGDDR5 “―Ψ≠ΫΞΫΞ≤ΜΡή¬ζΉψ»ΥΟ«Ε‘¥χΩμΒΡ–η“ΣΘ§ΦΦ θΖΔ’Ι“≤“―Ϋχ»κΝΥΤΩΨ±ΤΎΓΘΟΩΟκ‘ωΦ” 1 GB ΒΡ¥χΩμΫΪΜα¥χά¥ΗϋΕύΒΡΙΠΚΡΘ§’β≤Μ¬έΕ‘”Ύ…ηΦΤ»Υ‘±ΜΙ «œϊΖ―’Ώά¥ΥΒΕΦ≤Μ «“ΜΗωΟς÷«ΓΔΗΏ–ßΜρΚœΥψΒΡ―Γ‘ώΓΘ“ρ¥ΥΘ§GDDR5 ΫΪΜαΫΞΫΞΉηΑ≠œ‘Ω®–ΨΤ§–‘ΡήΒΡ≥÷–χ‘ω≥ΛΓΘHBM ÷Ί–¬Βς’ϊΝΥΡΎ¥φΒΡΙΠΚΡ–ß¬ Θ§ ΙΟΩΆΏ¥χΩμ±» GDDR5 ΗΏ≥ω 3 ±ΕΜΙΕύΓΘ“≤Φ¥ «ΙΠΚΡΫΒΒΆ3±ΕΕύΘΓHsvΩλ≥δΆχ¬γ
HsvΩλ≥δΆχ¬γ
 HsvΩλ≥δΆχ¬γ HsvΩλ≥δΆχ¬γ
HsvΩλ≥δΆχ¬γ
≥ΐΝΥ–‘ΡήΚΆΙΠΚΡΆβΘ§HBM ‘ΎΫΎ Γ≤ζΤΖΩ’ΦδΖΫΟφ“≤ΕάΨΏΫ≥–ΡΓΘΥφΉ≈”ΈœΖΆφΦ“Ε‘Ηϋ«α±ψΗΏ–ßΒΡΒγΡ‘ΉΖ«σΘ§HBM ”Π‘ΥΕχ…ζΘ§Υϋ–Γ«…ΒΡΆβ–ΈΝν»ΥΨΣΧΨΘ§ Ι”ΈœΖΆφΦ“Ω…“‘ΑΎΆ―±Ω÷ΊΒΡ GDDR5 –ΨΤ§Θ§ΨΓœμΗΏ–ßΓΘ¥ΥΆβΘ§HBM ±» GDDR5 ΫΎ ΓΝΥ 94% ΒΡ±μΟφΜΐΘΓHsvΩλ≥δΆχ¬γ
HsvΩλ≥δΆχ¬γ
 HsvΩλ≥δΆχ¬γ HsvΩλ≥δΆχ¬γ
HsvΩλ≥δΆχ¬γ
»γ…œΆΦΥυ ΨΘ§ΫΪ‘≠±Ψ‘ΎPCB…œΒΡGDDR5Ω≈ΝΘΘ§»Ϊ≤ΩΦ·≥…ΒΫΖβΉΑάοΚΆGPU“ΜΤπΓΘάœΧζΟ«ΥΒά¥Ηω ΒΦ ΒΡ≥Ώ¥γΆΦΩ¥Ω¥ΘΚΚΟΒΡΘ§»γœ¬ΆΦΘΚHsvΩλ≥δΆχ¬γ
HsvΩλ≥δΆχ¬γ
 HsvΩλ≥δΆχ¬γ HsvΩλ≥δΆχ¬γ
HsvΩλ≥δΆχ¬γ
Ρ«GPU+HBMΒΡ’ϊΗω–ΨΤ§ΒΫΒΉ”–Εύ¥σ≥Ώ¥γΡΊΘΩ»γœ¬ΘΚ ΚΆ’Τ–ΡάύΥΤΓΘHsvΩλ≥δΆχ¬γ
HsvΩλ≥δΆχ¬γ
 HsvΩλ≥δΆχ¬γ HsvΩλ≥δΆχ¬γ
HsvΩλ≥δΆχ¬γ
Ρ«”Ο ÷…œΒΡHBMΘ§Ήω≥…“ΜΗωœ‘Ω®–η“ΣΕύ¥σΒΡPCBΡΊΘΩΫ”Ή≈…œΆΦHsvΩλ≥δΆχ¬γ
HsvΩλ≥δΆχ¬γ
 HsvΩλ≥δΆχ¬γ HsvΩλ≥δΆχ¬γ
HsvΩλ≥δΆχ¬γ
4ΘΚHOW? HBMΆΤΕ·AI≥…ΙΠHsvΩλ≥δΆχ¬γ
»ΥΙΛ÷«ΡήΘ§‘ΤΦΤΥψΘ§…νΕ»―ßœΑ≥ωœ÷3ΗωΥψΝΠΫΉΕΈHsvΩλ≥δΆχ¬γ
ΒΎ“ΜΘ§‘γΤΎΘ§AI¥ΠάμΤςΦήΙΙΒΡΧΫΧ÷‘¥”Ύ―ß θΫγΒΡΑκΒΦΧεΚΆΧεœΒΦήΙΙΝλ”ρΘ§¥Υ ±ΡΘ–Ά≤ψ ΐΫœ…ΌΘ§ΦΤΥψΙφΡΘΫœ–ΓΘ§ΥψΝΠΫœΒΆΓΘHsvΩλ≥δΆχ¬γ
ΒΎΕΰΘ§ΡΘ–Ά÷πΫΞΦ”…νΘ§Ε‘ΥψΝΠ–η«σœύ”Π‘ωΦ”Θ§ΒΦ÷¬ΝΥ¥χΩμΤΩΨ±Θ§Φ¥IOΈ Χβ,¥Υ ±Ω…Ά®Ιΐ‘ω¥σΤ§ΡΎΜΚ¥φΓΔ”≈Μ·ΒςΕ»ΡΘ–Άά¥‘ωΦ” ΐΨίΗ¥”Ο¬ Β»ΖΫ ΫΫβΨωHsvΩλ≥δΆχ¬γ
ΒΎ»ΐΘ§‘ΤΕΥAI¥Πάμ–η«σΕύ”ΟΜßΓΔΗΏΆΧΆ¬ΓΔΒΆ―”≥ΌΓΔΗΏΟήΕ»≤Ω πΓΘΦΤΥψΒΞ‘ΣΨγ‘ω ΙIOΤΩΨ±”ζΦ”―œ÷ΊΘ§“ΣΫβΨω–η“ΣΗΕ≥ωΫœΗΏ¥ζΦέΘ®»γ‘ωΦ”DDRΫ”ΩΎΆ®Βά ΐΝΩΓΔΤ§ΡΎΜΚ¥φ»ίΝΩΓΔΕύ–ΨΤ§ΜΞΝΣΘ©HsvΩλ≥δΆχ¬γ
¥Υ ±,Τ§…œHBMΘ®High Bandwidth MemoryΘ§ΗΏ¥χΩμ¥φ¥ΔΤςΘ©ΒΡ≥ωœ÷ ΙAI/…νΕ»―ßœΑΆξ»ΪΖ≈ΒΫΤ§…œ≥…ΈΣΩ…ΡήΘ§Φ·≥…Ε»Χα…ΐΒΡΆ§ ±Θ§ Ι¥χΩμ≤Μ‘Ό ή÷Τ”Ύ–ΨΤ§“ΐΫ≈ΒΡΜΞΝΣ ΐΝΩΘ§¥”Εχ‘Ύ“ΜΕ®≥ΧΕ»…œΫβΨωΝΥIOΤΩΨ±ΓΘHsvΩλ≥δΆχ¬γ
HsvΩλ≥δΆχ¬γ
 HsvΩλ≥δΆχ¬γ HsvΩλ≥δΆχ¬γ
HsvΩλ≥δΆχ¬γ
…œΆΦΈΣΚ°ΈδΦΆΙΪΥΨΒΡDiaoNao AI ASIC…ηΦΤΘ§ΜΚ¥φ’ΦΟφΜΐΒΡ66.7%Θ®NBin+NBout+SBΘ©HsvΩλ≥δΆχ¬γ
ΨΓΙήΤ§…œΖ÷≤ΦΒΡ¥σΝΩΜΚ¥φΡήΧαΙ©ΉψΙΜΒΡΦΤΥψ¥χΩμΘ§ΒΪ”…”Ύ¥φ¥ΔΫαΙΙΚΆΙΛ“’÷Τ‘ΦΘ§Τ§…œΜΚ¥φ’Φ”ΟΝΥ¥σ≤ΩΖ÷ΒΡ–ΨΤ§ΟφΜΐΘ®Ά®≥ΘΈΣ1/3÷Ν2/3Θ©Θ§œό÷ΤΝΥΥψΝΠΧα…ΐΓΘHsvΩλ≥δΆχ¬γ
Εχ“‘HBMΈΣ¥ζ±μΒΡ¥φ¥ΔΤςΕ―ΒΰΦΦ θΘ§ΫΪ‘≠±Ψ“ΜΈ§ΒΡ¥φ¥ΔΤς≤ΦΨ÷ά©’ΙΒΫ»ΐΈ§Θ§¥σΖυΕ»ΧαΗΏΝΥΤ§…œ¥φ¥ΔΤςΒΡΟήΕ»Θ§ ΙAIΫχ»κ–¬ΒΡΖΔ’ΙΫΉΕΈΘ§HsvΩλ≥δΆχ¬γ
HBM–η“ΣΩΥΖΰΒΡ2¥σ÷ς“ΣΈ ΧβΘΚHsvΩλ≥δΆχ¬γ
1ΘΚHBM–η“ΣΫœΗΏΒΡΙΛ“’Εχ¥σΖυΕ»Χα…ΐΝΥ≥…±ΨΓΘHsvΩλ≥δΆχ¬γ
2ΘΚ¥σΝΩDRAMΕ―ΒΰΘ§ΚΆGPUΖβΉΑ‘Ύ“ΜΤπΘ§≤ζ…ζ¥σΝΩΒΡ»»Θ§»γΚΈ…Δ»» «ΦΪ¥σΒΡΧτ’ΫΓΘHsvΩλ≥δΆχ¬γ
ΉήΫα“ΜΨδΜΑΘΚHBMΨΆ «ΫΪΚήΕύDRAMΆ®Ιΐ3DΦΦ θΦ·≥…‘Ύ“ΜΗωΖβΉΑΡΎΘ§¬ζΉψΗς÷÷ΦΤΥψΕ‘ΗΏ¥χΩμΒΡ–η«σΓΘHsvΩλ≥δΆχ¬γ |

