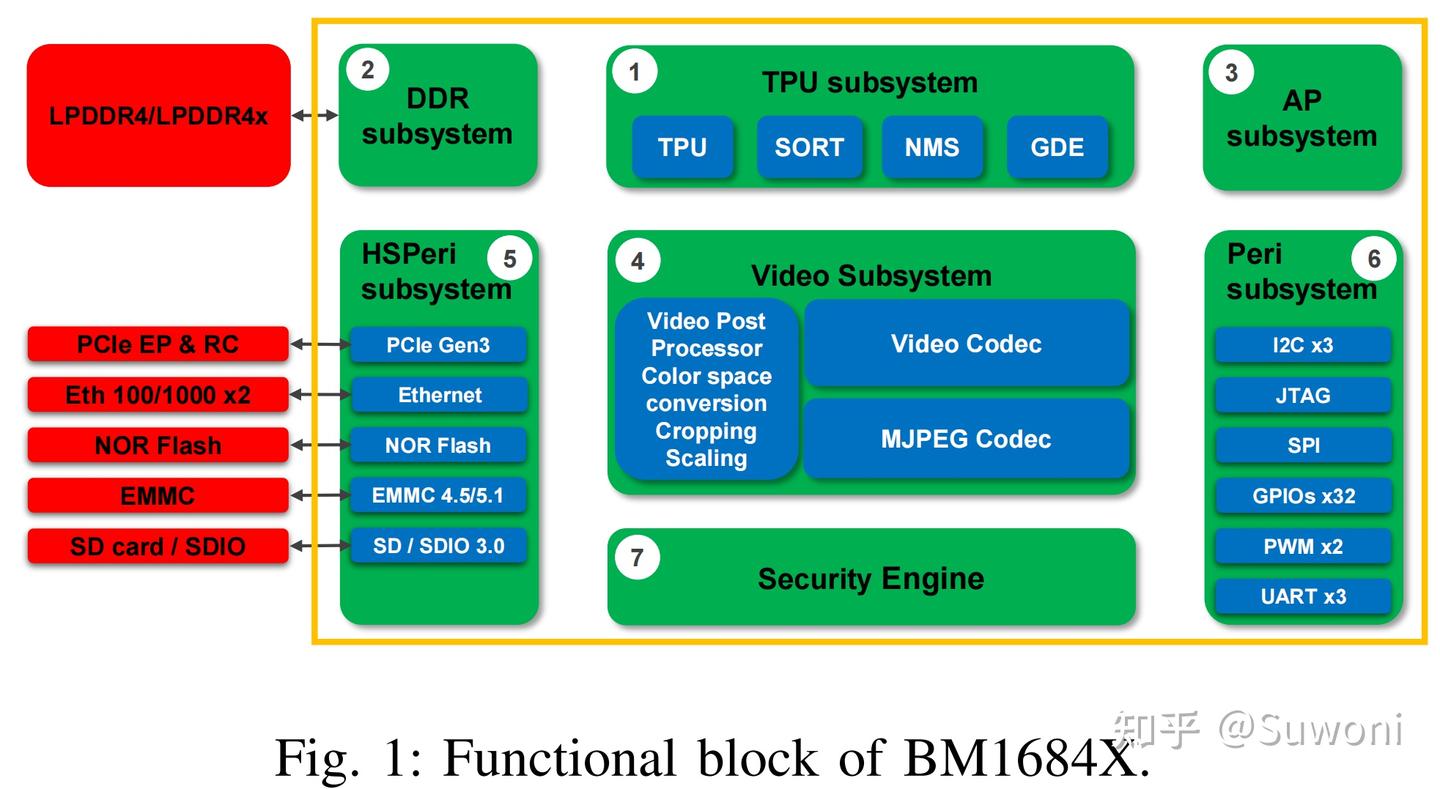
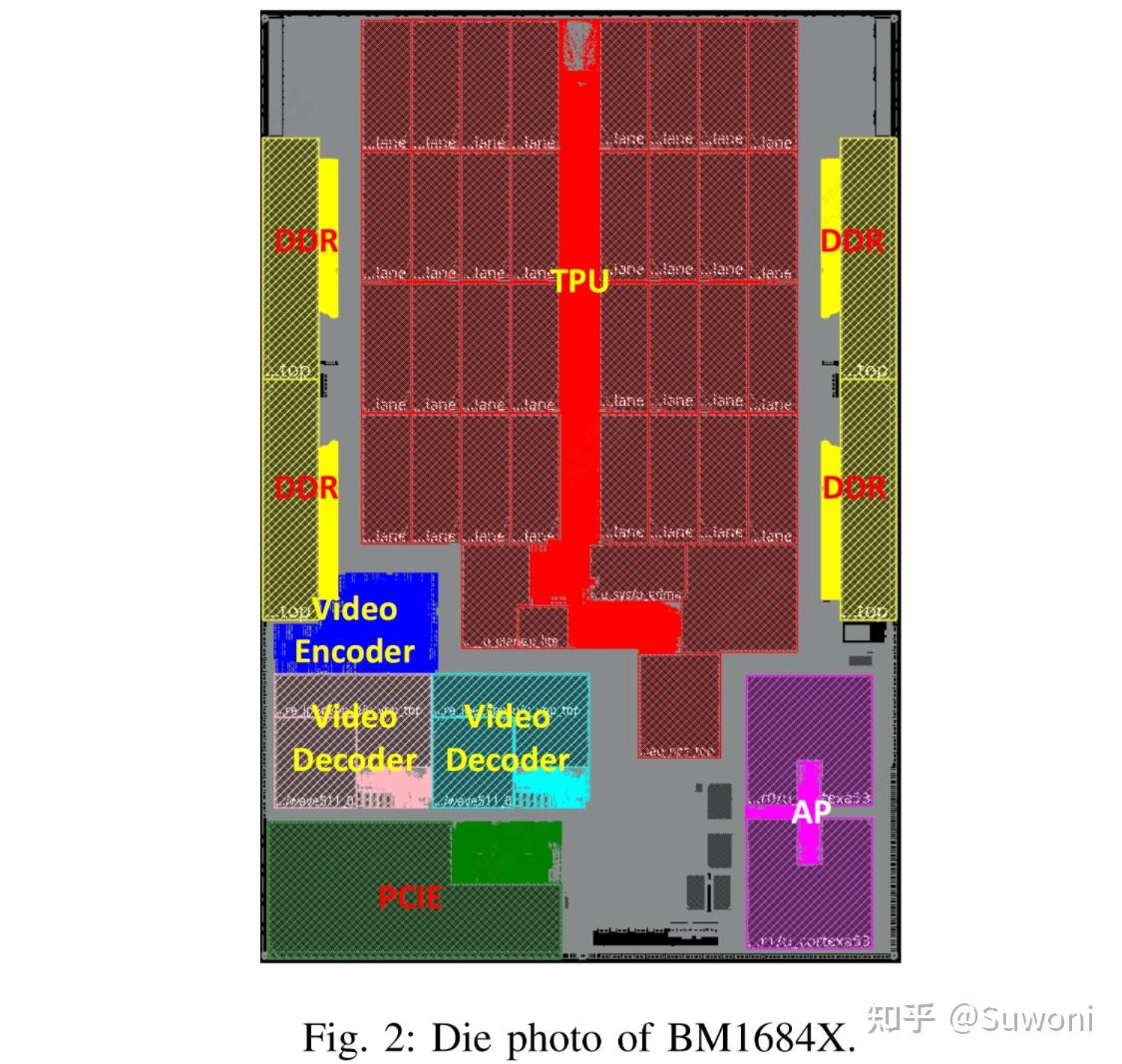
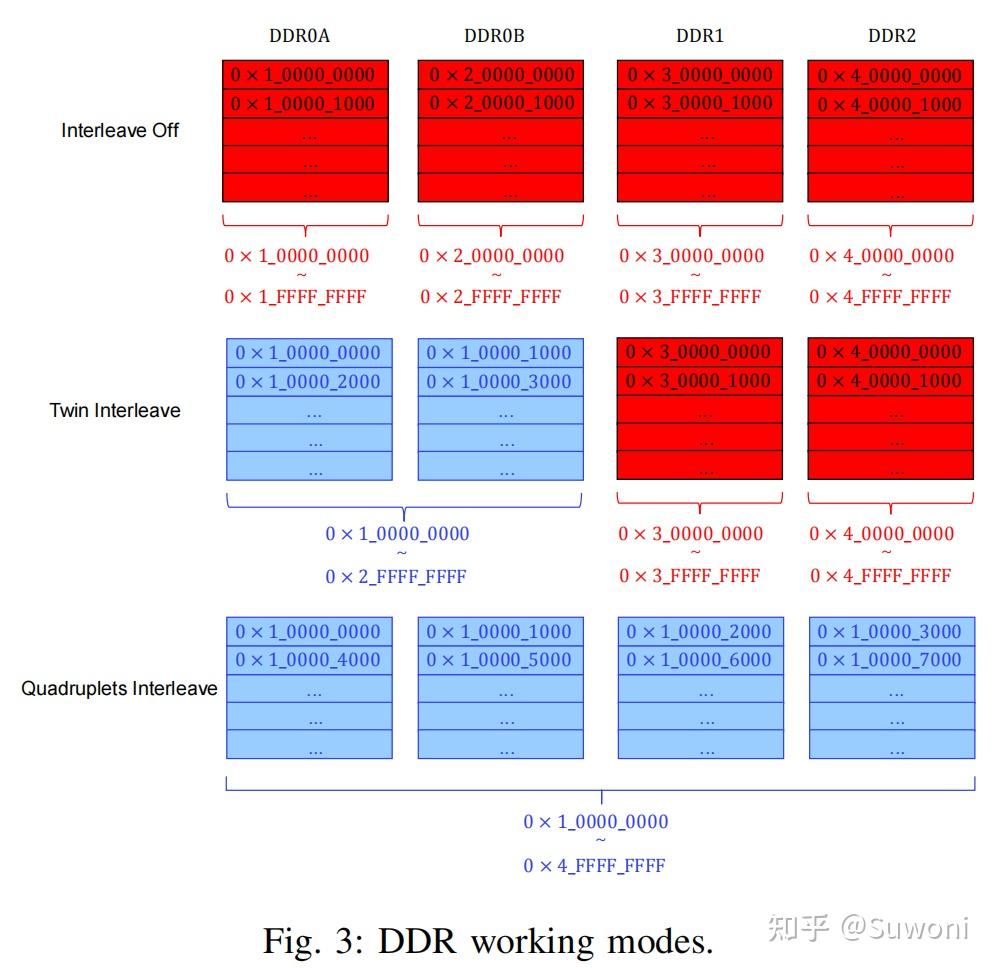
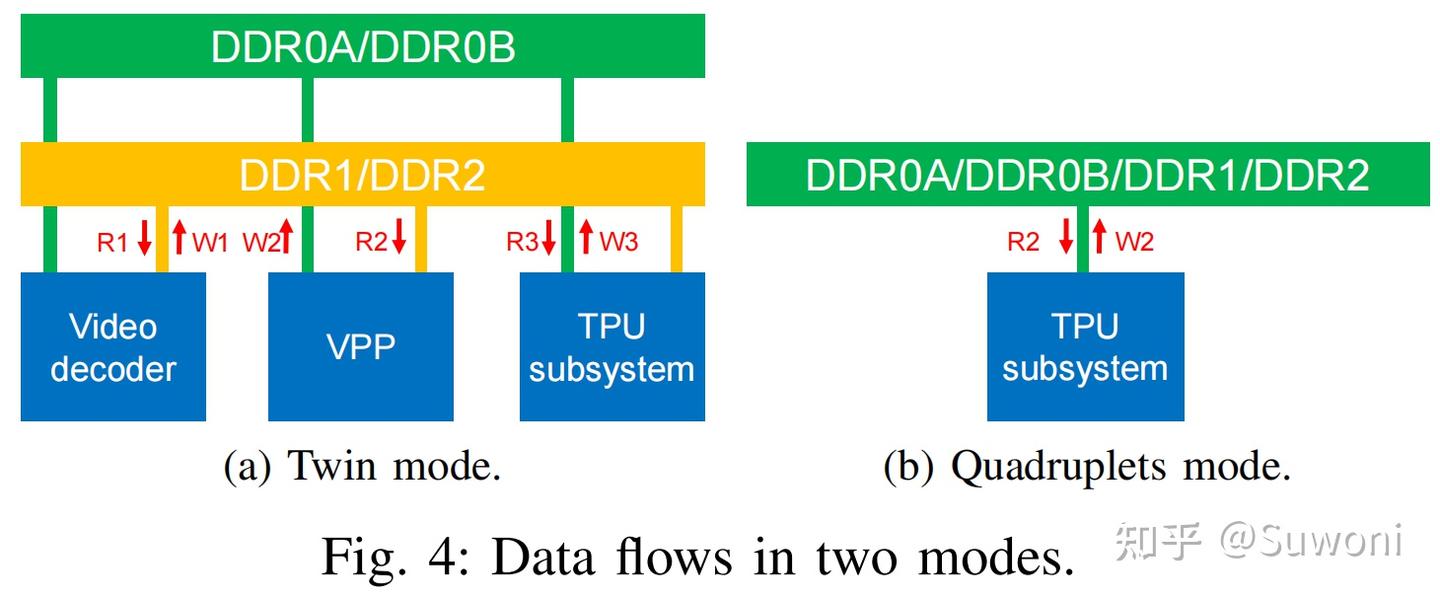
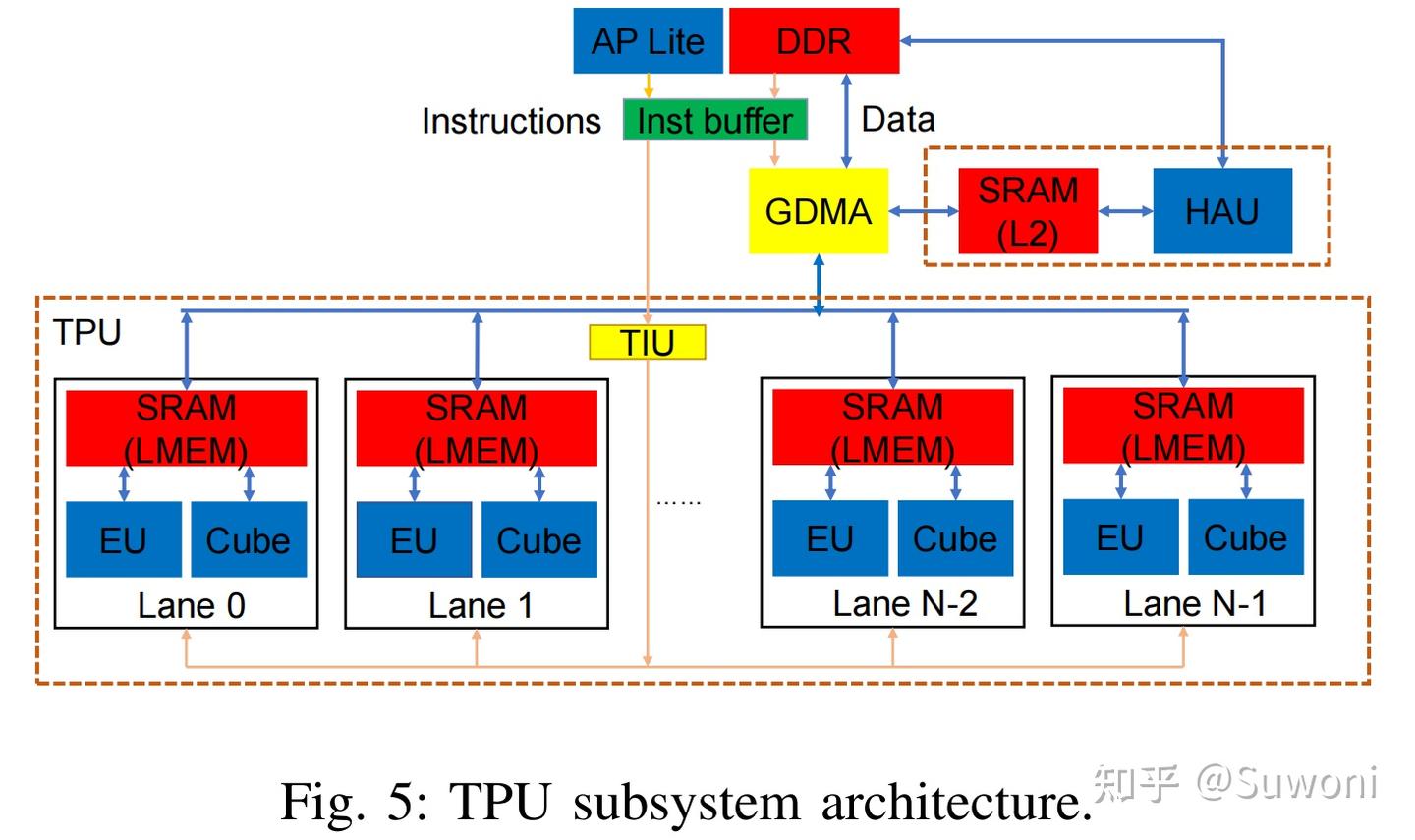
(通用 DMA)负责不同内存层级之间的数据搬运,包括 DDR、局部内存、本地 L2 缓存
AP Lite 以 PIO(程序化输入输出)模式工作,调度 TPU、GDMA 和 HAU 的执行,并根据需要处理标量计算。TPU、HAU、GDMA 拥有 AXI 从接口用于配置,AP Lite 则通过 AXI 总线对这些模块进行控制。
AP Lite(Application Processor Lite)是一个轻量级控制处理器模块,它不执行复杂的 AI 运算任务,而是用于协调和调度整个 TPU 子系统的工作。wLm快充网络
A. 超宽数据的 SIMD 架构
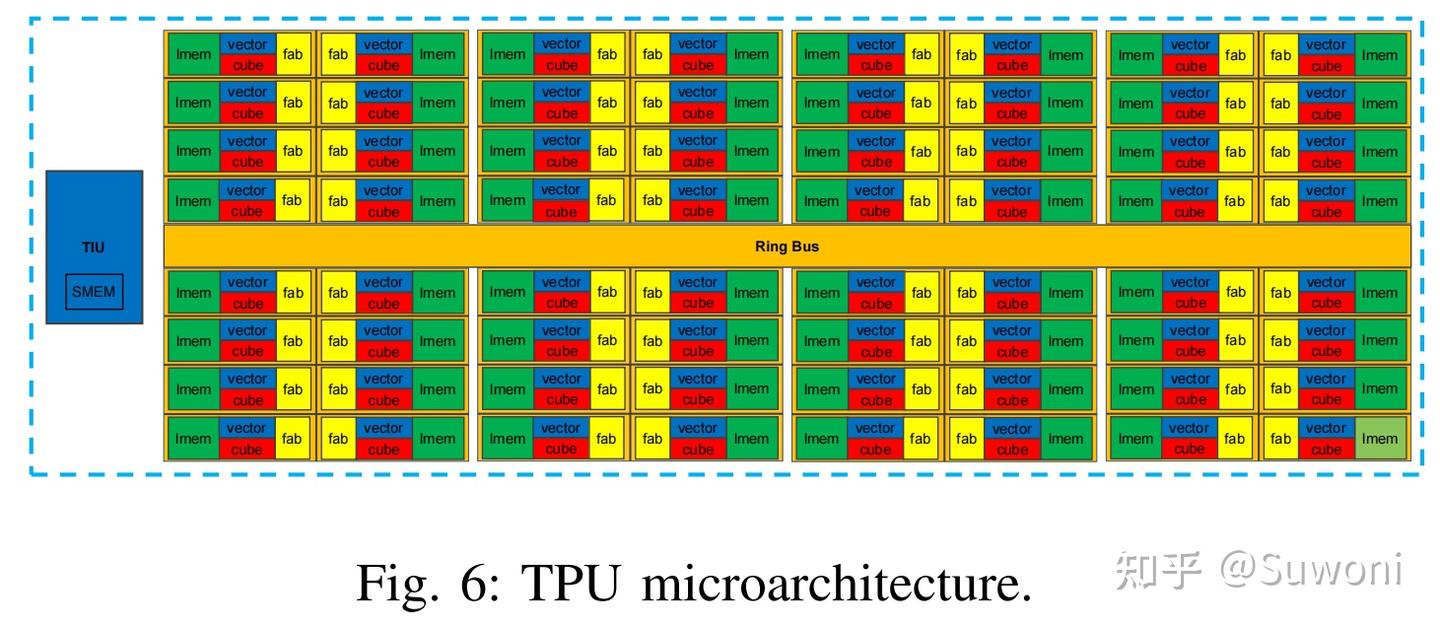
SIMD 是一种并行数据处理技术,在现代计算中被广泛采用,尤其适用于处理大规模数据。SIMD 架构允许一条指令同时操作多个数据。BM1684X 的 TPU 采用超大数据宽度的 SIMD 架构:
TIU 为控制单元;
Lane 为执行单元;
64 条 lane 构成了一个宽度为 32684 比特的矢量并行处理器
TIU 占用面积小,便于拓展新功能,而 lane 的结构保持稳定,设计变动较小。选择使用超宽 SIMD 架构的原因:
单次操作处理更多数据,大幅提高吞吐率;
尤其适合图像处理、科学计算、大数据分析等场景;
指令数量与执行时间大幅减少,能耗更低;
简化指令集设计与编程复杂度
B. TPU Lane 的微架构
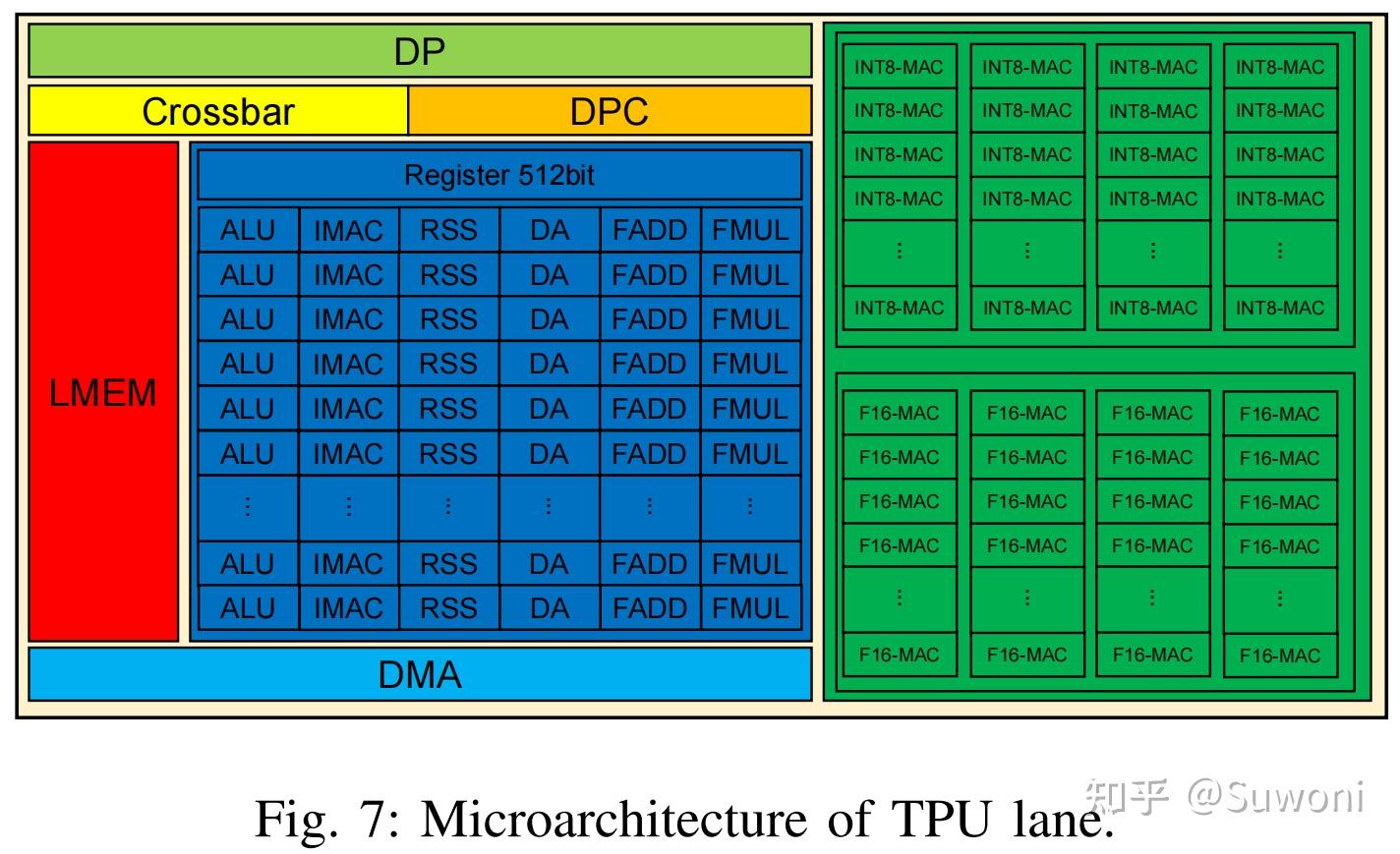
每条 lane 包括以下模块,微架构如图 7所示:
DP(调度器):协调控制信息,转发请求到对应模块;
DPC(数据路径控制器):处理操作数请求,读写数据;
LMEM(局部内存):每 lane 配备 256KB,读写带宽为 512-bit,具有双读双写口,但同一时间不能访问同一 bank;
DPDMA:处理 DMA 总线请求;
EU 和 CUBE:主要计算阵列,EU 支持多种运算,CUBE 专用于卷积和矩阵乘法
1. EU(执行单元):wLm快充网络
EU 包含多种运算模块:ALU、IMAC、RSS、FADD、FMUL、数据类型转换等
操作数和 eu_cmd(TIU 解码得到的控制信号)被送入 EU,执行完成后写回 LMEM
EU 采用数据流架构 ,由 TIU 发出的微指令(ucode)控制数据流:
可实现有向无环图或循环图结构的原子操作;
支持浮点开方倒数、除法等复杂流程;
为节省功耗与提高性能,TPU 不使用寄存器文件,直接用 SRAM 存取操作数;
通过指令融合与数据前传机制降低 SRAM 读写频率;
运算单元之间可复用中间结果,避免中间值写回 SRAM
2. CUBE:wLm快充网络
专用于卷积 / 矩阵乘法计算,支持:
INT8:每条 lane 上有 64×4 的 MAC 阵列,可并行处理 4 点部分和,总体为 64×64×4;
性能达 32 TOPS(1GHz 下);
权重可复用 16 次,有效节能;
通道方向的 64 维乘加可优化 MAC 单元面积与功耗
FP16/BF16:每 lane 有 32×4 MAC 阵列,总计为 64×32×4;
性能达 16 TOPS;
输出支持 FP16/BF16/FP32;
融合加法器减少面积与功耗,权重最多可复用 16 次;
支持按通道量化操作,无需额外周期,提升 CUBE 使用率
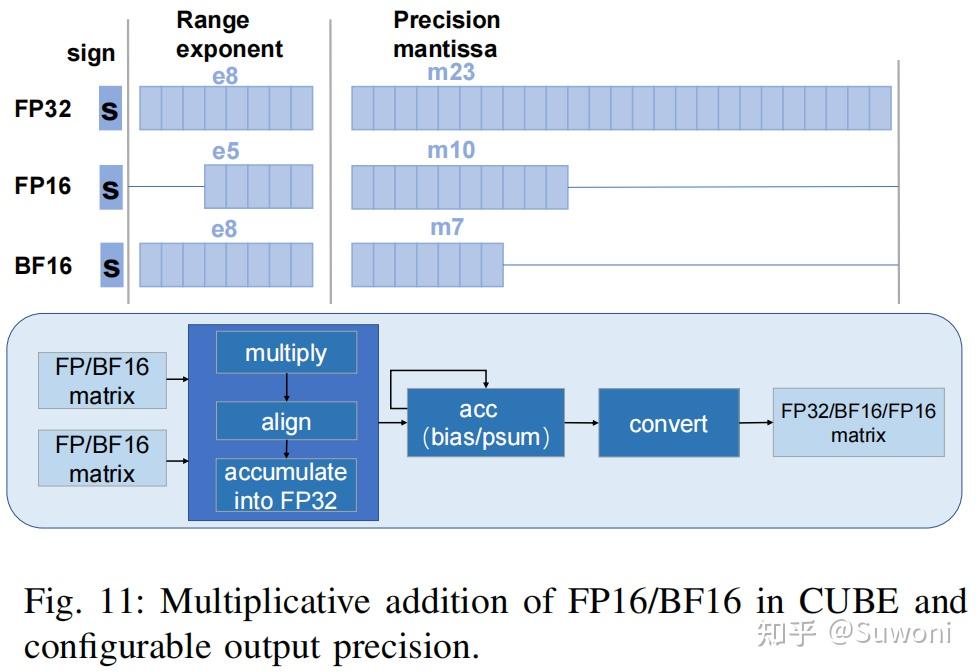
图 11 展示了在 CUBE 模块中进行 FP16/BF16 乘加运算并支持可配置输出精度的完整流程
执行流程说明:wLm快充网络 wLm快充网络 multiply(乘法) 将 FP16/BF16 数据两两相乘;align(对齐) 将不同指数位的数据对齐,以便进行加法;accumulate into FP32(累加为 FP32) 将累加结果临时提升为 FP32 精度,可避免 FP16/BF16 在累加过程中的精度丢失,这个中间过程称为 partial sum(psum) ;acc(bias / psum) 加上偏置(bias)或进行部分和累积,这一步也在 FP32 精度下进行,结果通过反馈路径返回参与下一步wLm快充网络
3. Crossbar(交叉开关):wLm快充网络
读取 LMEM 后,常需重新排列数据;
通过 64输入-64输出的 8-bit Crossbar 实现高性能数据聚合;
每 lane 上的 Crossbar 可用于生成 4 个 INT8 数据;
关键用于高效支持池化、深度卷积等结构重排密集型算子
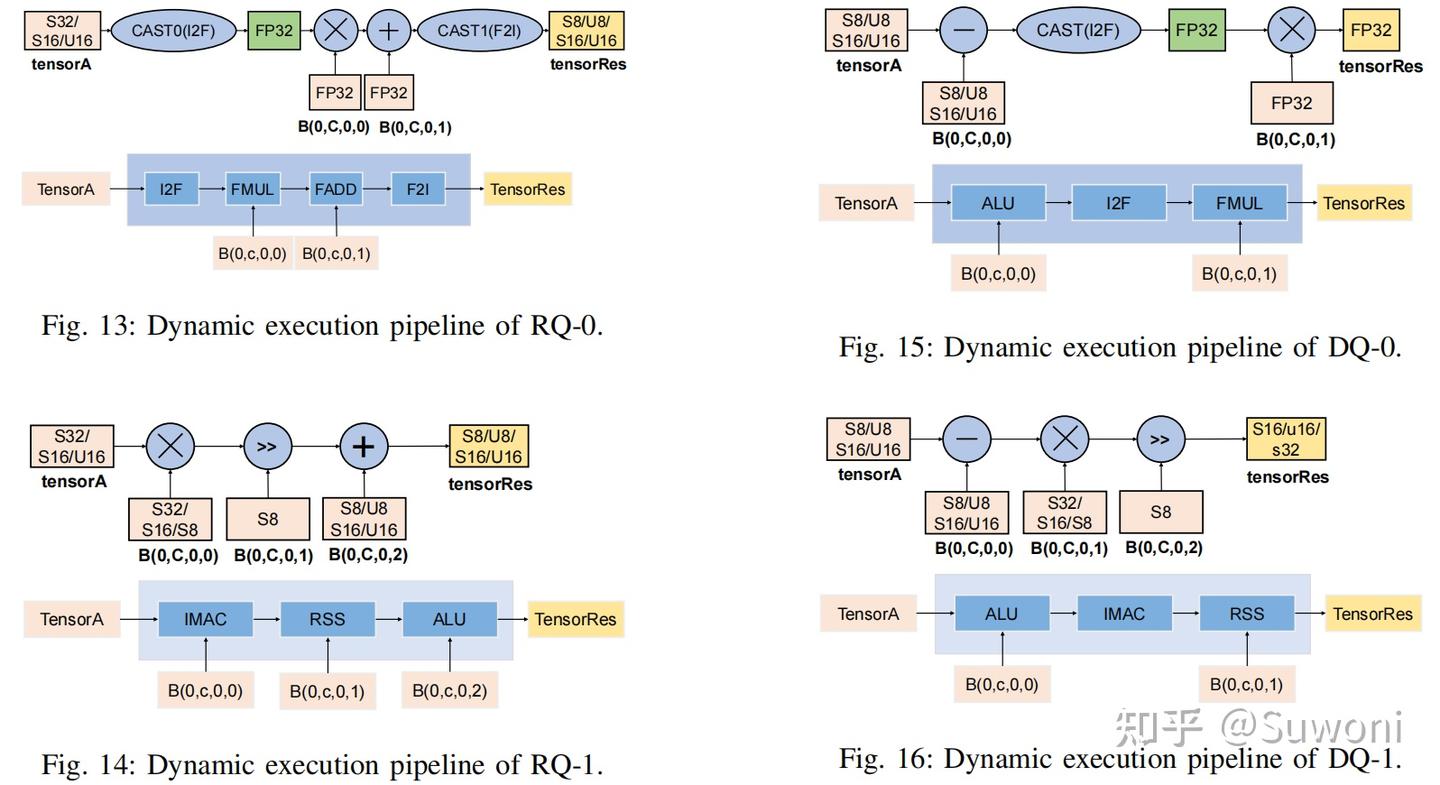
4. 动态流水线(Dynamic Pipeline):wLm快充网络
用于高效执行 RQ/DQ 操作:
举例:INT32 → FP32 → 乘以 scale(FP32)→ 加 zero-point(FP32)→ 转 INT8;
通过不同 eu_cmd 配置流水线结构,实现一周期完成复杂操作;
EU 对 DQ/RQ 提供了专用加速指令,支持动态数据流;
数据前传避免数据冒险,减少指令延迟;
指令融合降低指令数量与总执行时间
动态流水线的好处:
单条指令比多条单指令更简单;
融合后性能提升约 40%;
中间数据不写入 SRAM,经测试功耗下降 2/3;
提高指令密度与执行效率
图 13~16 展示了动态流水线的实现方式
C. HAU(硬件加速单元)
作者在设计的 HAU 中提出了 SORT(排序) 、NMS(非极大值抑制) 和 GDE(数据聚合引擎) 三个模块wLm快充网络
由于排序仅涉及矢量计算,而不涉及 TPU 擅长的矩阵乘法或卷积运算,因此在 HAU 中为其单独设计了一个运算加速器
支持的数据类型包括 INT32、UINT32 和 FP32
SORT 支持升序/降序、索引排序、TopK 操作,数据可存储于全局内存或 L2 缓存中
GDE 根据索引值,从源数据中收集符合条件的数据,并输出至目标数据中
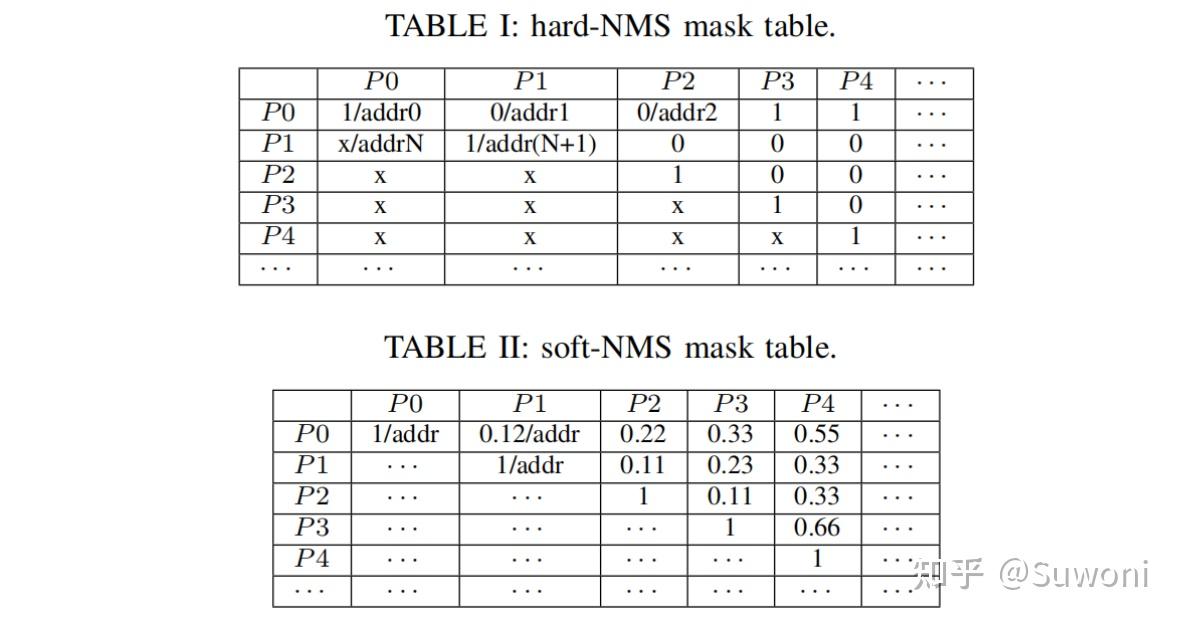
NMS 模块实现了非极大值抑制算法的后半部分(前半部分可由 TPU 完成并作为输入提供)。支持两种形式:
硬 NMS(Hard-NMS):
输入为 N×N 的掩码表;
表中每项为 INT8,1 表示 IoU(交并比)小于阈值或表示自身;
掩码表示意如 Table I 所示
软 NMS(Soft-NMS):
输入为 N×N 的衰减系数表(FP32),表示两个候选框之间的衰减程度;
根据最大分数决定保留框,并更新其余分数;
若有多个最大值,则取地址最小者;
更新后继续查找下一最大值,直到满足结束条件;
掩码表示如 Table II 所示
D. GDMA(通用 DMA)
GDMA 是 TPU 与 DRAM 之间进行数据搬运的重要模块 ,也支持:
DRAM↔TPU
DRAM↔DRAM
TPU↔TPU 的数据传输
典型运算流程如下:
使用 GDMA 将计算所需数据从 DRAM 搬入 TPU 内存;
启动 TPU 执行计算,结果保存在 TPU 内存;
再次启动 GDMA,将结果写回 DRAM
为什么不用传统 DMA?
传统 DMA 功能简单,仅支持块状数据搬运,无法满足 AI 算法的性能与灵活性需求
而 AI 模型处理的是高维张量(如 2D/3D/4D),常需要搬运张量的切片 ,而非连续数据
传统方案的问题包括:
需要多次控制启动 DMA,增加开销;
使用链表 + 描述符方式虽略好,但仍需较多控制数据,开销可能比传输数据还大,浪费带宽
BM1684X 设计了支持至多4 维张量(N, C, H, W) 的 GDMA 指令,
支持以下操作:
常规搬运
NC 维转置搬运
常数填充
广播复制等操作
相比传统 DMA,效率显著提升:
示例:传统 DMA 传输 channel 维度为 64 的张量需 64 条指令,GDMA 一条指令搞定;
CNN 等模型中常将数据连续排布,但因 SRAM 容量有限,编译器需切片处理,GDMA 可一次传输张量片段,传统 DMA 无法实现
GDMA 还支持更多高级操作
Non-Zero、Mask-Select、Scatter/Gather 等张量运算 (在预处理中常见);这些不是典型 SIMD 操作,TPU 内支持有限;
在 GDMA 中实现有三大优势:
边搬运边计算,减少传输数据量;
硬件效率高,避免异构计算下的缓存刷新等开销;
编程模型灵活,不依赖 TPU 特定结构
GDMA 支持 TPU↔TPU 直接通信:
TPU 的 SRAM 仅支持本 lane 操作,GDMA 可跨 lane 操作;
为多核 TPU 设计保留该能力,支持未来的多核协同场景,以双核为例:
核 1 做目标检测,核 2 做特征提取;
batch size=1 时并行跑同一模型,加速推理;
batch size 大时做 tensor 并行,共享 DRAM 减少访问;
某层计算量过大时,按层切分由多核联合计算
GDMA 的高效设计有助于 AI 加速器实现高性能、低功耗、去中心化的数据搬运,提升整体系统效率
E. TPU 子系统的编程模型
BM1684X 的 TPU 子系统支持两种运行模式:
PIO 模式(Programmed I/O):编程式运行,指令由 AP Lite 控制器直接执行
TPU 指令被编译为 AP Lite 专用二进制文件 ;
AP Lite 运行时动态生成 TPU/GDMA/HAU 的指令,并分发至对应模块;
每个模块有独立指令队列,并行取指并执行 ,提升资源利用率;
AP Lite 也具备标量计算能力 ,可访问 DDR、L2 和本地内存,协调计算与数据调度
DESC 模式(Descriptor):描述符驱动,预定义任务序列,适合动态任务
程序调用 TPU 内置接口时会生成 TPU 与 GDMA 指令
这些指令保存为二进制描述符文件,写入设备的 DDR
TPU 子系统直接从 DDR 中读取并执行这些指令序列
4 工具链
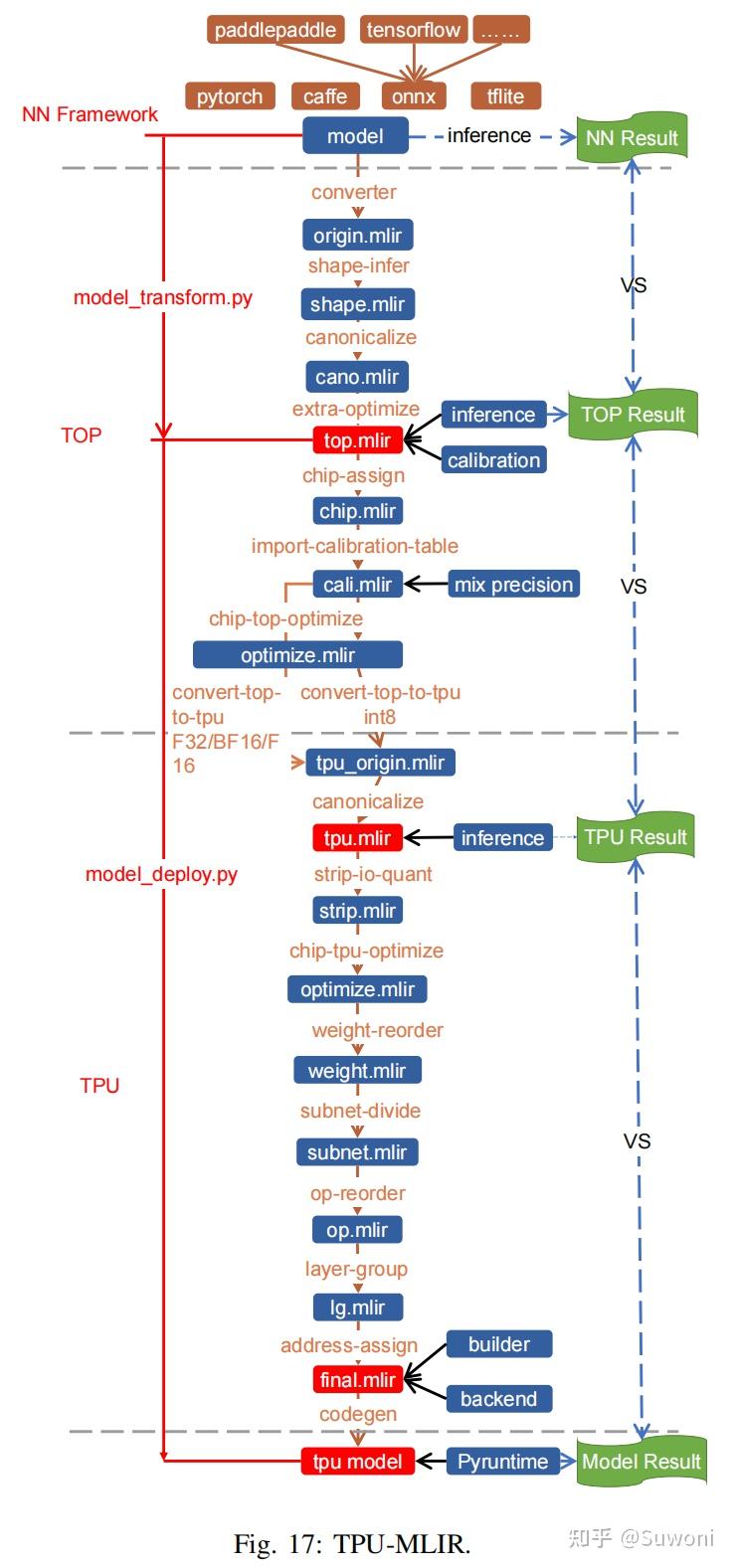
BM1684X 架构的发布伴随着一套前沿工具链的推出——TPU-MLIR(张量处理器多层中间表示工具链) 。这款新一代 TPU 工具链不仅保持了对前代系统的向后兼容性,同时还整合了一系列全新的功能特性。
跨框架支持能力
TPU-MLIR 的一个核心特点是:它可以无缝支持多种主流神经网络框架 ,包括:
PyTorch
ONNX
TensorFlow
PaddlePaddle
及其他框架
这种“全框架兼容性”设计,确保了不论底层使用哪个框架,处理流程都保持一致,从而实现统一、流畅的开发体验
分层设计:TOP 层 + TPU 层
TPU-MLIR 工具链采用分层架构,将神经网络模型抽象为两个层次:
TOP 层:处理与芯片无关的操作(通用),包括图优化、量化、推理
TPU 层:处理与芯片相关的操作(定制),如权重重排、算子切分、地址分配等
模型转换流程如图 17所示,模型会经过多个 Pass 转换,逐步变为最终的指令格式。下面是各 Pass 的作用:
TOP 层 Pass 列表:
shape-infer:推断各算子的张量形状(包括常量折叠);
canonicalize:对计算图进行简化优化,如将 ReLU 融合进 Conv、形状合并等;
extra-optimize:执行额外优化,如 FLOPs 计算、无效输出移除等;
processor-assign:指定所用处理器(如 BM1684X);
import-calibration-table:根据校准表为每个算子插入 min/max 值,便于后续量化;对称量化时插入 threshold;
processor-top-optimize:处理器相关的 TOP 层优化;
convert-top-to-tpu:将 TOP 层下沉为 TPU 层:若数据为浮点类型,直接转为 TPU 层对应算子;若为 INT8 类型,则需进行量化转换
TPU 层 Pass 列表:
canonicalize:TPU 层图优化,如连续 requantization 的合并;
strip-io-quant:判断输入/输出是否为量化类型,否则默认为 FP32;
processor-tpu-optimize:处理器相关 TPU 层优化;
weight-reorder:根据硬件特性重排权重(如卷积的 filter 和 bias);
subnet-divide:根据运行平台划分子网络(若全算子运行在 TPU,仅有一个子图);
op-reorder:调整算子执行顺序(如注意力机制的特殊处理);
layer-group:将尽可能多的算子划分为可在本地内存连续执行的子区段;
address-assign:为需要使用全局内存的算子分配地址;
codegen:调用各算子的 codegen 接口,生成指令缓冲区;
builder:将最终模型生成为 FlatBuffers 格式文件
精度验证与正确性保障
为了确保 TPU-MLIR 工具链的可靠性,采用了逐层比对验证 机制:
比对项
验证内容
TOP 层 ↔ ONNX
比较推理输出是否一致
TPU 层 ↔ TOP 层
检查 TPU 特定算子是否保持精度一致
TPU 层 ↔ C 模型仿真
最终硬件指令结果与软件模拟是否一致
这种比对策略确保了从高层模型到底层芯片指令的精度传递与正确执行
TPU-MLIR 工具链的一大优势是:每一次模型转换都会输出对应的 MLIR 表达 。这使得整个模型转换过程具有良好的可追踪性与可调试性,极大提升了开发效率与透明度
结论和经验教训
本文介绍了由 SOPHGO 开发的先进 AI 处理器 BM1684X,该处理器旨在满足各类 AI 应用中多样化的需求。wLm快充网络
BM1684X 的 TPU 采用了 超大数据宽度的 SIMD 架构 ,用于降低指令单元的面积比例,并提升计算密度。执行单元(EU)内的 定制加速指令 支持 动态流水线执行 ,从而减少指令总数与执行时间,显著提升了 TPU 在 RQ(量化)和 DQ(去量化)操作中的性能。TPU 内部的 CUBE 阵列 可在特征图的通道维上同时执行 64 对 INT8 操作数的乘加运算。通过采用加法树 而非传统加法器,实现了显著的面积与功耗优化,从而提升了 TPU 的能效。BM1684X 在每条执行通道内部还集成了一个 64 输入-64 输出的 8-bit crossbar ,用于高性能数据聚合,进一步加强了 TPU 架构内部的数据处理能力。该芯片还提供三种内存访问模式 ,以展现其在满足不同 AI 处理需求方面的灵活性,同时优化了在不同任务与负载下的 DRAM 利用效率。同时还设计了配套的 TPU-MLIR 工具链 ,其特点包括:多框架统一处理,模型抽象的分层设计,转换步骤的正确性验证以及全过程的可追溯性。wLm快充网络
BM1684X 在包括大模型在内的各类 AI 模型上均展现出卓越的高性能计算能力 。通过与业界领先芯片的全面评估对比,验证了 BM1684X 在面对复杂、苛刻 AI 工作负载时所具备的高效处理能力。本处理器的 算力利用率 / 计算效率 高于 Nvidia Jetson 中使用的 GPGPU + NVDLA 架构 。对于 CNN 网络(如 ResNet50),其核心算子是卷积,Jetson 不具备专门支持卷积的电路,而是通过 IMG2COL(图像转列) 方式将图像展开为矩阵进行计算,这种方式效率不高;相比之下,TPU 具备专门支持卷积操作的电路,因此在相同算力与 DRAM 带宽下,性能更优 。对于Transformer 网络(如 BERT),此类模型中算子结构较为简单,在此类网络中,本文提出的 TPU 与 Nvidia Jetson 的性能表现相当 。wLm快充网络